Flat File Schemas
|
DataWeave 2.1 is compatible with Mule 4.1. Standard Support for Mule 4.1 ended on November 2, 2020, and this version of Mule will reach its End of Life on November 2, 2022, when Extended Support ends. Deployments of new applications to CloudHub that use this version of Mule are no longer allowed. Only in-place updates to applications are permitted. MuleSoft recommends that you upgrade to the latest version of Mule 4 that is in Standard Support so that your applications run with the latest fixes and security enhancements. |
DataWeave can process several different types of data. For most of these types, you can import a schema that describes the input structure in order to have access to valuable metadata at design time.
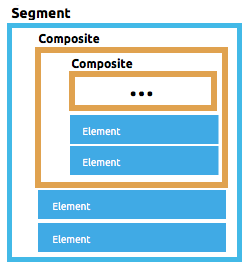
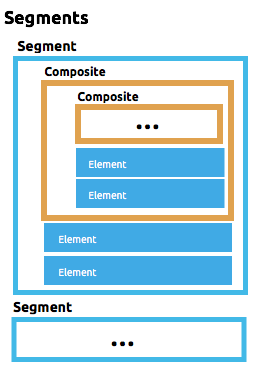
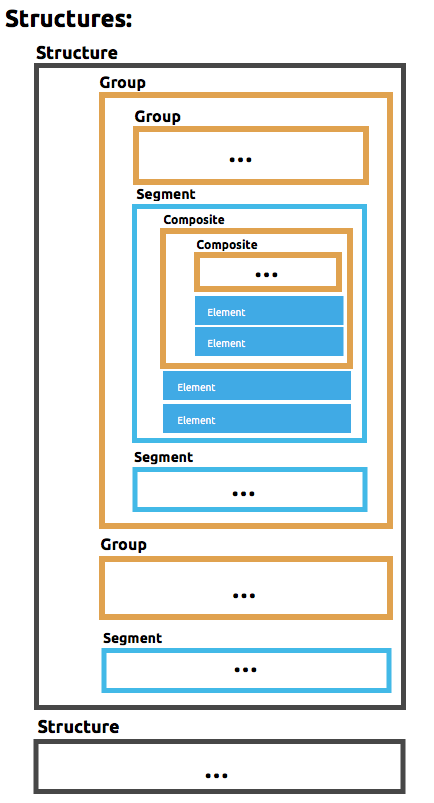
DataWeave uses a YAML format called FFD (for Flat File Definition) to represent flat file schemas. The FFD format is flexible enough to support a range of use cases, but is based around the concepts of elements, composites, segments, groups, and structures.
Schemas must be written in Flat File Schema Language, and by convention use a .ffs extension. This language is very similar to EDI Schema Language (ESL), which is also accepted by Anypoint Studio.
In DataWeave, you can bind your input or output to a flat file schema through a property.
Note that if you intend to use a simple fixed-width format, you can set up your data type directly through the Transform component using the Fixed Width type. Creating an instance of this type in Studio will automatically generate a matching schema definition.
Types of Components in a Schema
Here are the different types of components that make up a flat file schema, going from the most elementary to the more complex. Elements and Segments are always required, while Composites, Groups, and Structures might be needed depending on the top-level structure of your document.
-
Element - An element is a basic data item, which has an associated type and fixed width, along with formatting options for how the data value is read and written.
-
Composite - (Optional) A group of elements. It can also include other child composites.
-
Segment - A line of data, or record, made up of any number of elements and/or composites that might be repeated.
-
Group - (Optional) Several segments grouped together. It can also include other child groups.
-
Structure - A hierarchical organization of segments, which requires that the segments have unique identifier codes as part of their data.
Top-level structure of an FFD Document
The top-level definition in an FFD document starts with the form of the schema. In this case it must always be "FLATFILE", "COPYBOOK", or "FIXEDWIDTH". The differences between these forms are minor and mostly relate to how they are handled in Studio. The rest depends on the form of definitions present in the file, with the following alternatives:
-
Single segment - Segment information directly at the top level (including a
valueskey giving the element and/or composite details of the segment). -
Multiple segments - A
segmentskey with multiple child objects, each defining one segment. -
Multiple structures - A
structureskey with multiple child objects, each defining one structure.
Single Segment
If you are only working with one type of record, you only need to have a segment definition for that record type in your FFD.
This is a simple schema with only one segment:
form: FLATFILE
id: 'RQH'
tag: '1'
name: Request Header Record
values:
- { name: 'Organization Code', type: String, length: 10 }
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }The example above simply defines a list of elements within a single segment. It has no composites to group them into.
Here is another example:
form: FIXEDWIDTH
name: my-flat-file
values:
- { name: 'Row-id', type: String, length: 2 }
- { name: 'Total', type: Decimal, length: 11 }
- { name: 'Module', type: String, length: 8 }
- { name: 'Cost', type: Decimal, length: 8, format: { implicit: 2 } }
- { name: 'Program-id', type: String, length: 8 }
- { name: 'user-id', type: String, length: 8 }
- { name: 'return-sign', type: String, length: 1' }Note that simplified forms are only for convenience. You can use the segments key even if you only have a single child segment definition.
Multiple Segments
If you are working with multiple types of records in the same transformation, you need to use a structure definition that controls how these different records are combined.
In most cases, you need to define a way to distinguish between the different types of records. You do this by identifying tagValue fields as part of the record definitions. The parser will check the content of the fields of each record to identify the record type, then see how it fits into the defined structure.
This is an example of a complete structure schema with several component record types:
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
...Note that this example is not complete. It needs to define each of the referenced segments at the end. See Referenced versus Inlined Definitions to understand how these segments are being referenced in this example.
Multiple Structures
If you have multiple structures or segment definitions in an FFD, when you apply your schema to an metadata description on a Transform component, you need to specify which one you want to use.
A top-level structure of a schema with multiple structures might look like this:
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
usage: O
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
- id: 'BatchRsp'
name: Batch Response
data:
- { idRef: 'RSH' }
- groupId: 'Batch'
usage: O
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RSF' }
segments:
- id: 'RQH'
...The example defines two different structures, the BatchReq structure and the BatchRsp structure. Each of these structures uses a particular sequence of segments and groups of segments. The group Batch is repeated in both structures. A Batch group is composed of a single BCH line, multiple TDR lines, and a single BCF line.
Note that this example is not complete. It needs to define each of the referenced segments at the end. See Referenced versus Inlined Definitions to understand how these segments are referenced in this example.
Element Definitions
Element definitions are the basic building blocks of application data, consisting of basic key-value pairs for standard characteristics. Flat file schemas generally use inline element definitions, where each element is defined at the point it is used within a segment or composite structure, but you can also define elements separately and reference them as needed. Here are several element definitions defined for use by reference:
- { id: 'OrgCode', name: 'Organization Code', type: String, length: 10 }
- { id: 'CreatDate', name: 'File Creation Date', type: Date, length: 8 }
- { id: 'CreatTime', name: 'File Creation Time', type: Time, length: 4 }
- { id: 'BatchTransCount', name: 'Batch Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { id: 'BatchTransAmount', name: 'Batch Transaction Amount', type: Integer, format: { justify: zeroes }, length: 10 }The supplied id value is used as the idRef value when referencing one of these definitions as part of a segment or composite. Note that if you are defining elements inline within a segment definition (as opposed to defining them at the end of the document and referencing them), the id field is not required.
Element definitions might have the following attributes, classified by Form as applying to inline definitions, referenced definitions (as in the above example), or references to definitions:
| Name | Description | Form |
|---|---|---|
|
Number of occurrences (optional, default is |
Inline or reference |
|
Element identifier |
Referenced definition |
|
Element identifier |
Reference |
|
Element name (optional) |
All |
|
Value type code, as listed below |
Inline, or referenced definition |
|
Type-specific formatting information |
Inline, or referenced definition |
|
Number of character positions for value |
Inline, or referenced definition |
|
Value for this element used to identify a segment (see the Full Schema Example) |
Inline, or referenced definition |
The allowed types for defining an element are:
| Name | Description |
|---|---|
Boolean |
Boolean value |
Date |
Unzoned date value with year, month, and day components (which might not all be shown in text form) |
DateTime |
Unzoned date/time value with year, month, day, hour, minute, second, and millisecond components (which might not all be shown in text form) |
Decimal |
Decimal number value, which might or might not include an explicit decimal point in text form |
Integer |
Integer number value |
Packed |
Packed decimal representation of a decimal number value |
String |
String value |
Time |
Unzoned time value with hour, minute, second, and millisecond components (which might not all be shown in text form) |
Zoned |
Zoned decimal (Cobol format) |
Value types support a range of format options that affect the text form of the values. These are the main options, along with the types to which they apply:
| Key | Description | Applies to |
|---|---|---|
implicit |
Implicit number of decimal digits (used for fixed-point values with no decimal in text form) |
Decimal, Packed, Zoned |
justify |
Justification in field (LEFT, RIGHT, NONE, or ZEROES, the last only for numbers) |
All except Packed |
pattern |
For numeric values, the |
Date, DateTime, Decimal, Integer, Time |
sign |
Sign usage for numeric values (UNSIGNED, NEGATIVE_ONLY, OPTIONAL, ALWAYS_LEFT, ALWAYS_RIGHT) |
Decimal, Integer, Zoned |
signed |
Signed versus unsigned flag |
Packed |
Composite Definitions
Composites serve to reference a list of elements that are typically presented together. For example, firstName and lastName can be bundled together into a single composite because they are likely to be referred to as a group. Grouping elements into a composite also allows the list to be repeated.
Composite definitions are very similar to segment definitions, composed of some key-value pairs for standard characteristics along with lists of values. Composites might include both references to elements or other nested composites and inlined definitions. This is a example of a composite definition:
- id: 'DateTime'
name: 'Date/Time pair'
values:
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }Composite definitions might have the following attributes:
| Name | Description | Form |
|---|---|---|
|
Value from containing level giving actual number of occurrences (only used with |
Inline definition, or on reference |
|
Number (or maximum number, if |
Inline definition, or on reference |
|
Composite identifier for references |
|
|
Composite name (optional) |
Inline or referenced definition |
|
List of elements and composites within the composite |
Inline or referenced definition |
The values list takes the same form as the values list in a segment definition.
Segment Definitions
A segment describes a type of record in your data. Segments are mainly composed of references or direct definitions of elements and composites, together with some key-value pairs that describe the segment. In a somewhat complex schema, you might have a structure that contains two different segments, where one of these describes the fields that go in the single header of a bill of materials (such as date and person), while the other segment describes the recurring fields that go into each of the actual items in the bill of materials.
This is a sample segment definition that includes one simple element and a composite with two elements within:
- id: 'RQH'
name: Request Header Record
values:
- { name: 'Organization Code', type: String, length: 10 }
- id: 'DateTime'
name: 'Date/Time pair'
values:
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }Segment definitions might include the following attributes:
| Section | Description |
|---|---|
|
Segment identifier (unused for inline definitions, required for referenced definitions) |
|
Segment name (optional) |
|
List of elements and composites within the segment (either inlined, or references) |
Structure Definitions
Structure definitions are composed of a list of references to segments and group definitions, as well as a set of key-value pairs for standard characteristics. Segments may be further organized into groups consisting of a potentially repeated sequence of segments.
Here’s a sample structure definition again:
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
...This example includes references to two segments at the top level (RQH and RQF), as well as a group definition Batch that includes references to other segments (BCH, TDR and BCF). Note that for this structure to work, each of the referenced segments needs to be defined. See Referenced versus Inlined Definitions to understand how segments are referenced in this example.
A structure definition can contain the following attributes:
| Structure Key/Section | Description |
|---|---|
|
Structure identifier |
|
Structure name (optional) |
|
List of segments (and groups) in the structure |
Each item in a segment list is either a segment reference (or inline definition) or a group definition (always inline).
Group Definitions
A group definition can have the following attributes:
| Value | Description |
|---|---|
|
The group identifier |
|
Usage code, which might be |
|
Maximum repetition count value, which might be a number or the special value |
|
List of segments (and potentially nested groups) making up the group |
Referenced Versus Inlined Definitions
Besides the choice of top-level form, you also have choices when it comes to representing the components of a structure, segment, or composite. You can define the component segments, composites, and elements inline at the point of use, or you can define them in a table and reference them from anywhere. Inlining definitions is simpler and more compact, but the table form allows definitions to be reused. Table form examples must include an id value, and each reference to that definition uses an idRef. This example shows how this applies to the segments making up a structure:
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
name: "Request File Header Record"
values:
- { idref: createDate }
- { idref: createTime }
- { idref: fileId }
- { idref: currency }
- id: 'RQF'
name: "Request File Footer Record"
values:
- { idref: batchCount }
- { idref: transactionCount }
- { idref: transactionAmount }
- { idref: debitCredit }
- { idref: fileId }
elements:
- { id: createDate, type: Date, length: 8 }
- { id: createTime, type: Time, length: 4 }
- { id: fileId, type: String, length: 10 }
- { id: currency, type: String, length: 3 }
- { id: batchCount, type: Integer, format: { justify: zeroes }, length: 4 }
- { id: transactionCount, type: Integer, format: { justify: zeroes }, length: 6 }
- { id: transactionAmount, type: Integer, format: { justify: zeroes }, length: 12 }
- { id: debitCredit, type: String, length: 2 }In the above example, the BatchReq structure references segments in the data definition section. The segments are each then defined in the segments section at the top level of the schema, and these in turn reference elements that are later defined in the elements section.
An inlined definition of the same structure looks like this:
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
name: "Request File Header Record"
values:
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }
- { name: 'Unique File Identifier', type: String, length: 10 }
- { name: 'Currency', type: String, length: 3 }
- id: 'RQF'
name: "Request File Footer Record"
values:
- { name: 'File Batch Count', type: Integer, format: { justify: zeroes }, length: 4 }
- { name: 'File Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'File Transaction Amount', type: Integer, format: { justify: zeroes }, length: 12 }
- { name: 'Type', type: String, length: 2 }
- { name: 'Unique File Identifier', type: String, length: 10 }Full Example Schema
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
name: "Request File Header Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'RQH' }
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }
- { name: 'Unique File Identifier', type: String, length: 10 }
- { name: 'Currency', type: String, length: 3 }
- id: 'BCH'
name: "Batch Header Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'BAT' }
- { name: 'Sequence Number', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Batch Function', type: String, length: 1, tagValue: 'H' }
- { name: 'Company Name', type: String, length: 30 }
- { name: 'Unique Batch Identifier', type: String, length: 10 }
- id: 'TDR'
name: "Transaction Detail Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'BAT' }
- { name: 'Sequence Number', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Batch Function', type: String, length: 1, tagValue: 'D' }
- { name: 'Account Number', type: String, length: 10 }
- { name: 'Amount', type: Integer, format: { justify: zeroes }, length: 10 }
- { name: 'Type', type: String, length: 2 }
- id: 'BCF'
name: "Batch Footer Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'BAT' }
- { name: 'Sequence Number', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Batch Function', type: String, length: 1, tagValue: 'T' }
- { name: 'Batch Transaction Amount', type: Integer, format: { justify: zeroes }, length: 10 }
- { name: 'Type', type: String, length: 2 }
- { name: 'Batch Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Unique Batch Identifier', type: String, length: 10 }
- id: 'RQF'
name: "Request File Footer Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'RQF' }
- { name: 'File Batch Count', type: Integer, format: { justify: zeroes }, length: 4 }
- { name: 'File Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'File Transaction Amount', type: Integer, format: { justify: zeroes }, length: 12 }
- { name: 'Type', type: String, length: 2 }
- { name: 'Unique File Identifier', type: String, length: 10 }This example contains a single structure named 'BatchReq' with 5 components segments, using a doubly-nested structure of file and batch data for the segments. Each batch contains repeating detail records. All element definitions are in-lined.
The BatchReq structure definition requires that the data will consist of:
-
A single record that corresponds to the segment
RQH -
One or more records that correspond to the segment
BCH -
For each
BCHrecord, one or moreTDRrecords giving details of a particular transaction -
For each
BCHrecord, aBCFrecord following any containedTDRrecords -
A final, single record that corresponds to the segment
RQF
For this example every record starts with a three-character Record Type field with a specified tagValue. In the case of the batch records, the record type is further specified by a Batch Function tagValue.
This is a sample of data matching the schema example:
RQH201809011010A000000001USD
BAT000001HACME RESEARCH A000000001
BAT000002D01234567890000032876CR
BAT000003D01234567880000087326CR
BAT000004T0000120202CR000002A000000001
BAT000005HAJAX EXPLOSIVES A000000002
BAT000006D12345678900000003582DB
BAT000007D12345678910000000256CR
BAT000008T0000003326DB000002A000000002
RQF0002000008000000116876CRA000000001The lines in the example match the defined structure as listed below:
-
1
RQH(Request File Header Record) identified by the "RQH" value in the first three characters -
2
BCH(Batch Header Record) identified by the "BAT" value in the first three characters combined with the 'H' character in position 10 -
3-4
TDR(Transaction Detail Record) identified by the "BAT" value in the first three characters combined with the 'D' character in position 10 -
5
BCF(Batch Footer Record) identified by the "BAT" value in the first three characters combined with the 'T' character in position 10 -
6
BCH(Batch Header Record) identified by the "BAT" value in the first three characters combined with the 'H' character in position 10 -
7-8
TDR(Transaction Detail Record) identified by the "BAT" value in the first three characters combined with the 'D' character in position 10 -
9
BCF(Batch Footer Record) identified by the "BAT" value in the first three characters combined with the 'T' character in position 10 -
10
RQF(Request File Footer Record) identified by the "RQF" value in the first three characters
tagValue fields provide a lot of flexibility. The above example shows using a single tagValue for some record types, while adding a second tagValue for others, but you can also use completely different fields (or even disjoint sets of fields) for a tagValue, as long as you provide enough details for the parser to distinguish between the different types of records.
Note that older versions of the documentation showed a different way of distinguishing records based on tag values, using tagStart and tagLength values for the structure and tag values for the segments. This method of distinguishing segments is much more limited than the tagValue approach, and is now deprecated.