Streaming Data Processing with DataMapper
Especially useful when working with large datasets, Anypoint DataMapper supports streaming data input and output. For example, when reading information from a very large input file, you can use streaming you avoid having DataMapper load the whole file into memory. Instead, DataMapper works as a pipeline: it sequentially reads the file and store the data in a cache, performs data mapping, sends the output to the next transformer, empties the cache, then begins again. Using this procedure, DataMapper can parse a 500 MB CSV file using only about 75 MB of RAM, resulting in significant improvements in performance and resources utilization.
-
Anypoint DataMapper streaming supports CSV and fixed width input and output formats.
-
You can configure the size of the stream cache to optimize for performance.
Assumptions
This document assumes the reader is familiar with the Anypoint DataMapper Transformer. For a listing of all available tools in DataMapper, consult the DataMapper Visual Reference.
Setting Streaming in DataMapper
-
To set the Streaming parameter in your data mapping flow, click the Properties icon at the top-right of the DataMapper view, to open the Pattern Properties window.
-
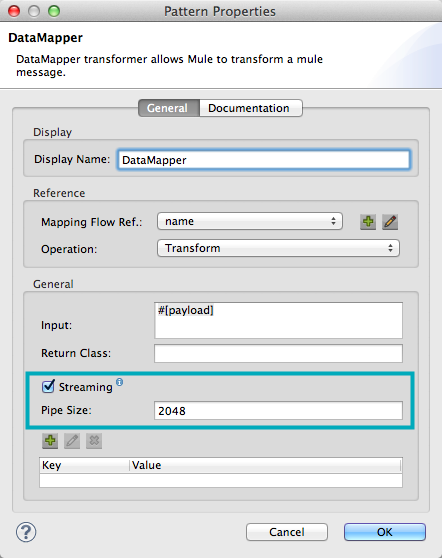
Click Streaming.
-
In the Pipe Size input field, enter the desired size of the cache. The default is 2048.
-
When working with files, the value of Pipe Size is expressed in bytes.
-
When working with collections, the value is expressed in number of collection elements.
-
Handling Exceptions
If an exception occurs in the mapping, DataMapper stops the streaming engine as soon as possible. To avoid undesired consequences in case of failure (such as inserting only part of a row into a database) use Transactions.
Example
This example illustrates the use of the Streaming feature in Anypoint DataMapper.
An HTTP Endpoint receives a CSV file, then passes it to DataMapper. DataMapper maps the input data from CSV to POJO. A Database (JDBC) Endpoint inserts the data into an external database. In this scenario, DataMapper and the Database endpoint work in parallel as a pipeline, further improving application performance.
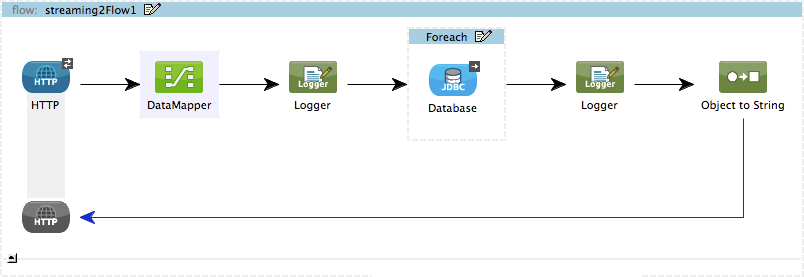
The image below displays the DataMapper view as configured for this example.
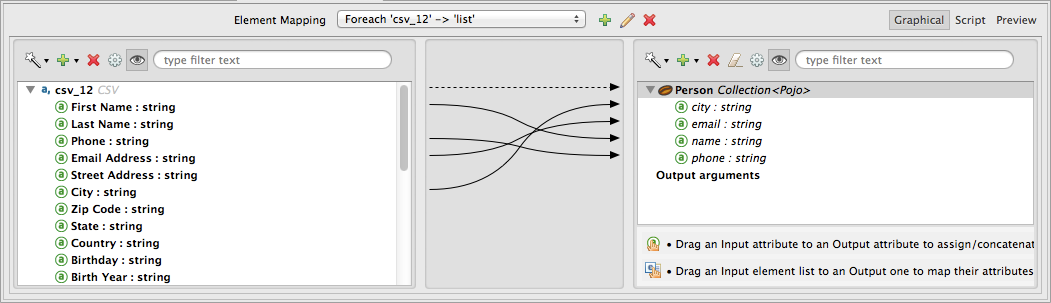
Finally, the JDBC output endpoint receives the list of maps, then incorporates each item as a value in the SQL query for the external database.
INSERT INTO Persons (name, city, email, phone) VALUES (#[payload.name], #[payload.city], #[payload.email], #[payload.phone])