Handling Errors During Batch Job
|
Standard Support for Mule 4.1 ended on November 2, 2020, and this version of Mule reached its End of Life on November 2, 2022, when Extended Support ended. Deployments of new applications to CloudHub that use this version of Mule are no longer allowed. Only in-place updates to applications are permitted. MuleSoft recommends that you upgrade to the latest version of Mule 4 that is in Standard Support so that your applications run with the latest fixes and security enhancements. |
Overview
Handling errors inside a batch job can be complicated considering the huge amount of data this scope is designed to take.
When processing 1 million records, it’s almost impossible to log everything. Logs would become huge, unreadable, and would take a massive toll on the performance of your processing.
On the other hand, logging too little would make it impossible for you to know what went wrong. And considering that if out of those 1 million records, 30 thousand of them failed, not knowing what’s wrong with them can turn your debugging task very problematic. This trade-off is not simple to overcome.
Logs of Failing Records Inside a Batch Step
When processing a batch job instance, a processor inside a batch step may fail or raise an error. When this occurs – perhaps because of corrupted or incomplete record data – Mule logs the stack traces following this logic:
-
Mule gets the exception’s full stack trace.
-
Mule strips that stack trace from any messages.
Even if all records raise the same error, the messages being processed would probably contain specific information related to those records. For example, if I’m pushing leads to my Salesforce account and one record fails because the lead was already uploaded, another repeated lead would have different record information, but the error is the same. -
Mule verifies if the stack trace was already logged in the current step.
If this was the first time the runtime encountered this error, it logs the error and showing a message like this:com.mulesoft.mule.runtime.module.batch.internal.DefaultBatchStep: Found exception processing record on step 'batchStep1' for job instance 'Batch Job Example' of job 'CreateLeadsBatch'. This is the first record to show this exception on this step for this job instance. Subsequent records with the same failures will not be logged for performance and log readability reasons:Mule logs on a "by step" basis. If another step also raises the same error, the runtime logs it again for that step.
-
When the batch job reaches the On Complete phase, Mule displays an error summary with every error type, and how many times it happened in each batch step.
The error summary for a batch job with two batch steps that raised abatch.exceptiontype:************************************************************************************************************************ * - - + Exception Type + - - * - - + Step + - - * - - + Count + - - * ************************************************************************************************************************ * com.mulesoft.mule.runtime.module.batch.exception.B * batchStep1 * 10 * * com.mulesoft.mule.runtime.module.batch.exception.B * batchStep2 * 9 * ************************************************************************************************************************Here we can see that the first step failed ten times and the second failed nine.
Mule logs batch errors using this behavior as its default configuration, which only logs INFO level messages to get a balanced trade-off between logging efficiency for large chunks of data.
However, your motivation to use batch processing might not be its ability to handle large datasets, but its capacity to recover from a crash and keep processing a batch job from where it was left off when performing "near real-time" data integration. Or you may need more verbose log levels for debugging.
For those cases, you can set the batch category to DEBUG level in your application’s log4j configuration like this:
log4j.logger.com.mulesoft.module.batch=DEBUG| Use the DEBUG level with care. Definitively not advised for production environments unless you’re sure that your jobs will not handle significantly large data sets. |
DataWeave Functions for Error Handling
Mule 4.x includes a set of DataWeave functions that you can use in the context of a batch step.
| DataWeave Function | Description |
|---|---|
#[Batch::isSuccessfulRecord()] |
A boolean function that returns true if the current record has not thrown exceptions in any prior step. |
#[Batch::isFailedRecord()] |
A boolean function that returns true if the current record has thrown exceptions in any prior step. |
#[Batch::failureExceptionForStep(String)] |
Receives the name of a step as a String argument. If the current record threw exception on that step, then it returns the actual Exception object. Otherwise it returns null |
#[Batch::getStepExceptions()] |
Returns a java |
#[Batch::getFirstException()] |
Returns the Exception for the very first step in which the current record has failed. If the record hasn’t failed in any step, then it returns null. |
#[Batch::getLastException()] |
Returns the Exception for the last step in which the current record has failed. If the record hasn’t failed in any step, then it returns null. |
Example
Imagine a batch job that polls files containing contact information.
In the first step, the batch job aggregates the contacts information and transforms them using the Transform Message component to then being pushed to Salesforce.
In the second step, the job transforms the same contacts again to match the data structure of another third-party contacts application (say, Google Contacts for example) and pushes them to this service using HTTP request.
Now, assume that as a third step, you need to be able to write into a JMS dead-letter queue per each record that has failed. To keep it simple, let’s say that the message will be the exception itself. This requirement holds a trick: each record could have failed in both steps, which means that the same record would translate into two JMS messages.
Such an application would look like this:

Since the goal is to gather failures, it makes sense to configure the Failures step with an ONLY_FAILURES filter. (see Refining Batch Steps Processing for more details about batch filters).
The set-payload processor in this step can be configured to use the #Batch::getStepExceptions() function.
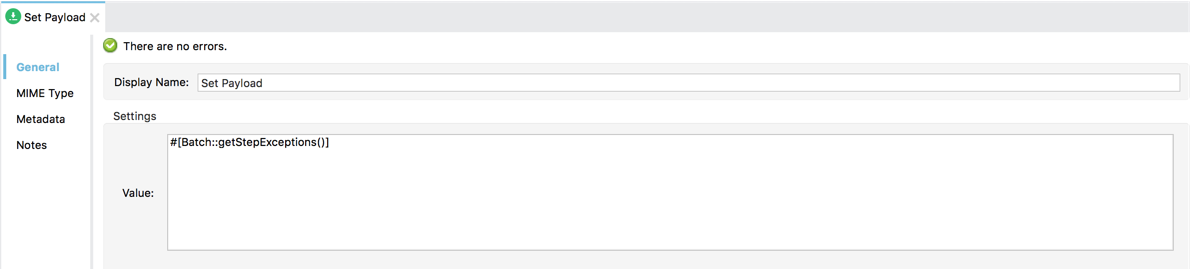
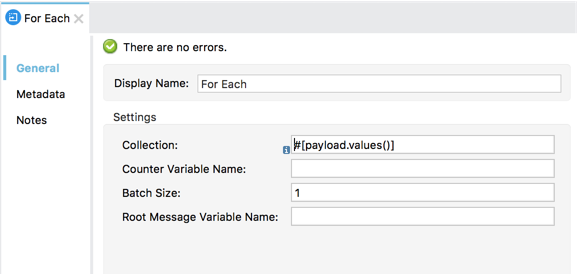
As stated above, this function returns a map with all errors found in all steps. And since our goal is to send the exceptions through JMS and we don’t care about the steps, we can use a foreach scope to iterate over the map’s values (the errors) and send them through a JMS outbound endpoint:
Batch Processing Strategies for Error Handling
Mule has three options for handling a record-level error:
-
Finish processing Stop the execution of the current job instance. Finish the execution of the records currently in-flight, but do not pull any more records from the queues and set the job instance into a
FAILUREstate. The On Complete phase is invoked. -
Continue processing the batch regardless of any failed records, using the
acceptExpressionandacceptPolicyattributes to instruct subsequent batch steps how to handle failed records. -
Continue processing the batch regardless of any failed records (using the
acceptExpressionandacceptPolicyattributes to instruct subsequent batch steps how to handle failed records), until the batch job accumulates a maximum number of failed records at which point the execution will halt just like in option 1.
By default, Mule’s batch jobs follow the first error handling strategy which halts the batch instance execution. The above behavior is controlled through the maxFailedRecords attributes.
| Failed Record Handling Option | Batch Job | |
|---|---|---|
Attribute |
Value |
|
Stop processing when a failed record is found. |
|
|
Continue processing indefinitely, regardless of the number of failed records. |
|
|
Continue processing until reaching maximum number of failed records. |
|
|
<batch:job jobName="Batch1" maxFailedRecords="0">Crossing the Max Failed Threshold
When a batch job accumulates enough failed records to cross the maxFailedRecords threshold, Mule aborts processing for any remaining batch steps, skipping directly to the On Complete phase.
For example, if you set the value of maxFailedRecords to "10" and a batch job accumulates ten failed records in the first of three batch steps, Mule does not attempt to process the batch through the remaining two batch steps. Instead, it aborts further processing and skips directly to On Complete to report on the batch job failure.
If a batch job does not accumulate enough failed records to cross the maxFailedRecords threshold, all records – successes and failures – continue to flow from batch step to batch step; use filters to control which records each batch step processes.